Web Application Security
Boost Your Application Security: How to Leverage GCP Cloud Armor for an Extra Layer of Protection

With the rise of the digital era, security of internet facing applications is essential. This includes the distribution of denial-of-service attacks, malicious bots and web application vulnerabilities that can majorly affect your reputation. Google Cloud Armor provides a robust solution in order to fortify the application’s defenses. This blog is helpful for developers that want to know how Cloud Armor bolsters your application security on Google Cloud Platform (GCP).
What to Explore
What is Cloud Armor?
Cloud Armor is a global Web Application Firewall (WAF) and DDoS mitigation service provided by GCP. It can be positioned in front of your internet-facing applications to act as a security shield, filtering malicious traffic before it reaches your backend servers. Cloud Armor provides a multi-layered defense against various risks as given below.
DDoS Attacks: Cloud Armor assures availability of service during traffic surges and safeguards your applications from volumetric (L3/L4) and Layer 7 DDoS attacks. This is how you can use GCP Cloud Armor to protect against DDoS attacks.
Web Application Attacks (WAF): You can mitigate common web vulnerabilities like SQL injection and cross-site scripting (XSS) by pre-configured WAF rules based on OWASP Top 10 risks.
Cloud Armor Benefits
- Enhanced Security: Cloud Armor safeguards your applications from a broad spectrum of threats and offers a comprehensive security solution.
- Improved Performance: Cloud Armor reduces the load on your backend servers and enhances application performance by filtering malicious traffic at the edge.
- Simplified Management: It provides a user-friendly interface for managing security policies and monitoring traffic patterns.
- Global Scale: Consistent protection across all your GCP regions is assured by globally distributed network ensures.
Reference:
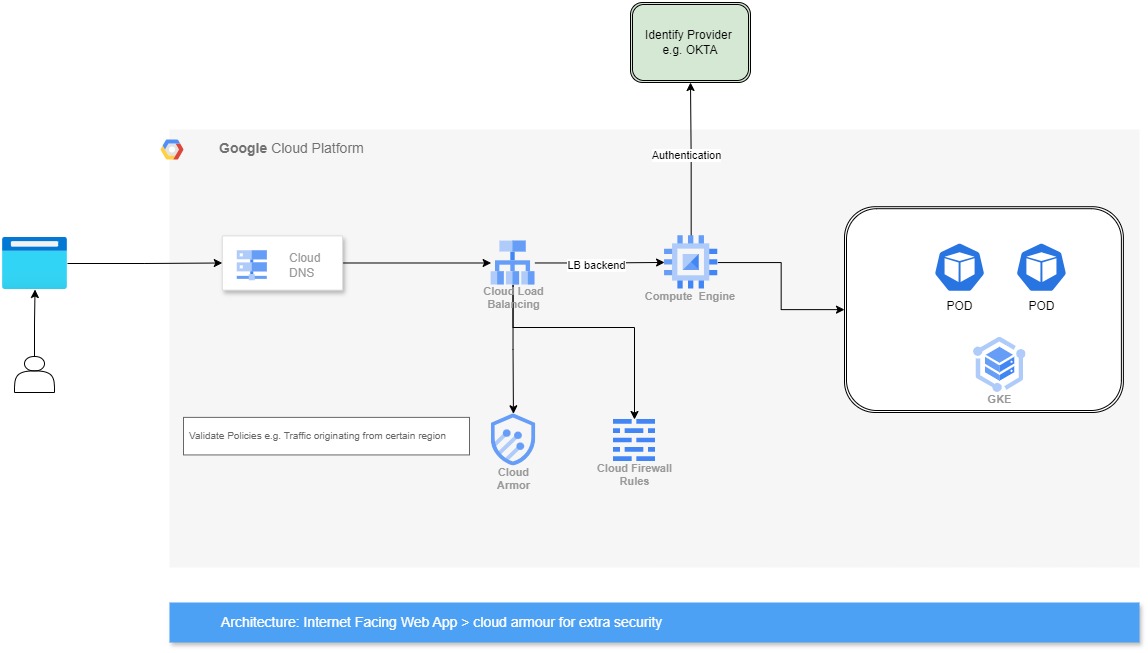
- Users access your application on the internet.
- Traffic is routed through Cloud Load Balancing, which can be integrated with Cloud Armor.
- Cloud Armor’s WAF engine inspects incoming traffic, filtering out malicious requests based on pre-configured rules or custom policies.
- Legitimate traffic is forwarded to your application servers / backend services.
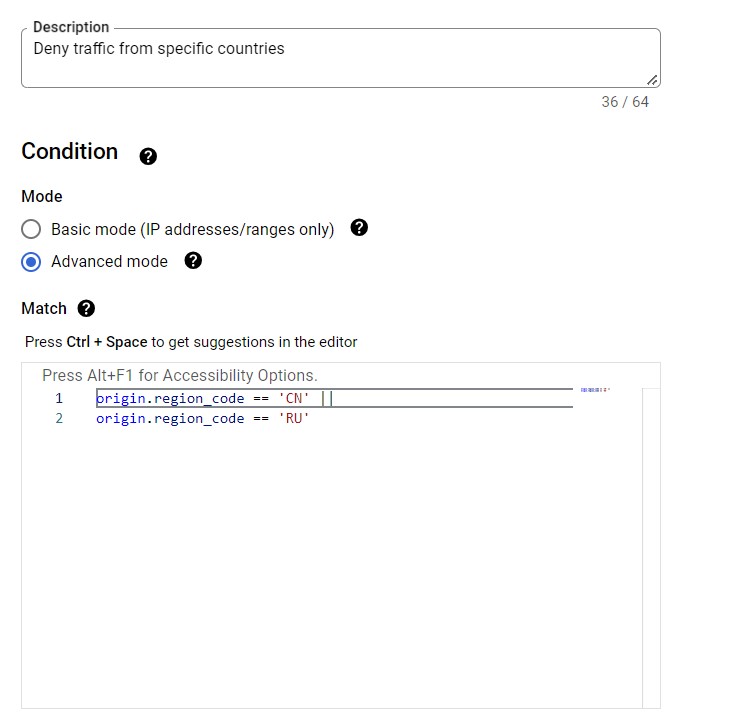
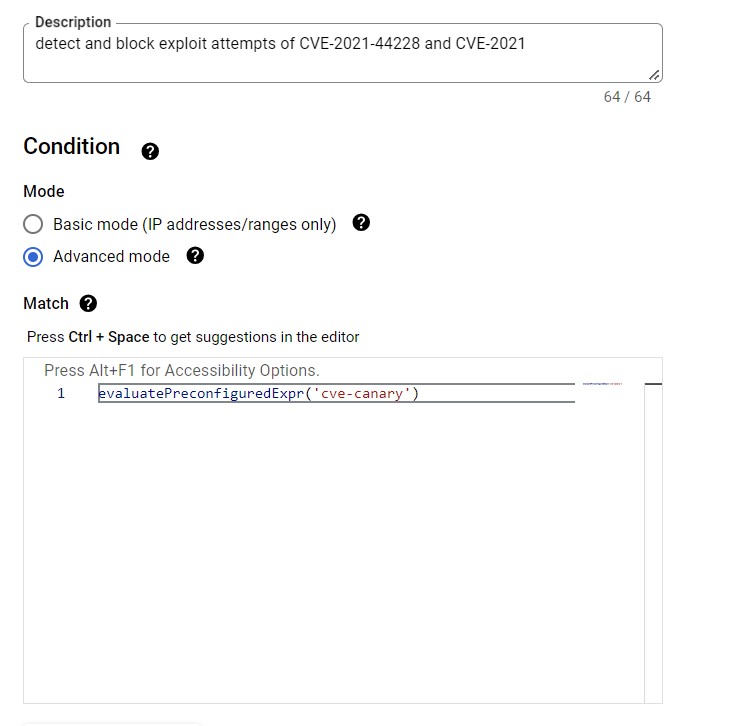
Sample Policy for reference –
Pros and Cons of using Cloud Armor
Benefits of using GCP Cloud Armor for web application security:
- Provides web application vulnerabilities and security against DDoS attacks.
- Better application performance and availability.
- User-friendly interface and simplified security management.
- Scalable protection that adapts to your application’s traffic patterns.
Drawbacks of using GCP Cloud Armor:
- Additional cost associated with Cloud Armor usage.
- Might need configuration adjustments for existing applications.
- Might add slight latency because of additional processing at the edge.
Cost Considerations
The charges of configuring GCP Cloud Armor for optimal protection are based on incoming and outgoing request counts. You can leverage GCP’s free tier for limited usage. Pay-as-you-go pricing applies for exceeding the free tier limits. Refer to GCP’s pricing documentation for detailed cost information
https://cloud.google.com/armor/pricing.
Conclusion
GCP Cloud Armor offers a comprehensive security solution for your internet-facing applications on Google Cloud Platform. It safeguards your applications from a wide range of threats, improves performance, simplifies management, and provides global protection. While there are additional costs and potential configuration adjustments, the benefits of enhanced security, improved application health, and user-friendly management outweigh the drawbacks for most organizations. Contact Us to discuss your application security needs with our experts and determine if Cloud Armor aligns to your objectives.
Recommended Content

You Might Also Like



Data Security

