ETL Migration
Navigating the Data Modernization landscape and diving into the Data Lakehouse concept and frameworks

In today’s data-driven world, organizations are constantly striving to extract meaningful insights from their ever-expanding datasets. To achieve this, they need robust platforms that can seamlessly handle the complexities of data processing, storage, and analytics. In this blog, we’ll delve into the concept of data lakehouse that has emerged to address these challenges along with data warehouse.
What to Explore
The Rise of the Data Lakehouse
Traditionally, organizations had to choose between data warehouses and data lakes, each with its own strengths and limitations. Data warehouses excelled at providing structured and optimized data storage, but often struggled to accommodate the diversity and volume of modern data. On the other hand, data lakes allowed for flexible and scalable storage of raw data, but faced challenges when it came to organizing and querying that data effectively.
The Data Lakehouse, a term popularized by Databricks, aims to bridge this gap by combining the strengths of both data warehouses and data lakes. It offers a unified platform that supports structured and semi-structured data, enabling users to perform complex analytics, machine learning, and AI (Artificial Intelligence) workloads on a single architecture. The Data Lakehouse architecture provides the foundation for a more streamlined and efficient data management process.
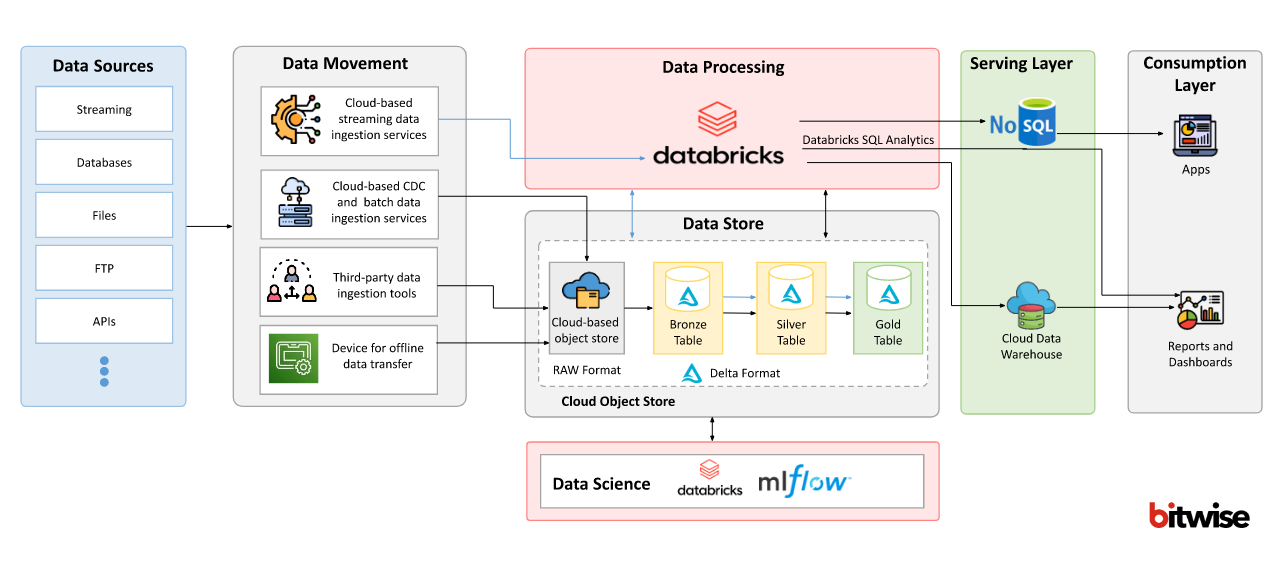
The Databricks Advantage
Databricks, a leading unified analytics platform, has emerged as a pivotal player in the realm of Data Lakehouse solutions. The company’s cloud-based platform integrates data engineering, data science, and business analytics, providing organizations with a collaborative environment to drive innovation and insights from their data.
Key Features of the Databricks Data Lakehouse
Unified Analytics: Databricks’ platform offers a unified approach to analytics, enabling data engineers, data scientists, and analysts to work collaboratively on the same dataset. This eliminates data silos and promotes cross-functional insights.
Scalability: With the ability to process large volumes of data in parallel, Databricks Data Lakehouse solution scales effortlessly to accommodate growing data needs, ensuring high performance even as data volumes increase.
Advanced Analytics: The platform supports advanced analytics capabilities, including machine learning and AI, empowering organizations to derive predictive and prescriptive insights from their data.
Data Governance and Security: Databricks places a strong emphasis on data governance and security, providing features that ensure data quality, lineage, and access control, making it a reliable choice for enterprises dealing with sensitive data.
Ecosystem Integration: Databricks seamlessly integrates with a wide array of data sources, storage systems, and analytics tools, allowing organizations to build and deploy end-to-end data pipelines.
Benefits and Impact
Data Lakehouse concept has brought about transformative benefits for organizations across various industries:
Accelerating Data Modernization with Databricks Lakehouse
Data lakehouse architecture provides a key component to enabling advanced analytics and AI capabilities that businesses need to stay competitive, but enterprises with substantial legacy enterprise data warehouse (EDW) footprint may find struggles to bridge the gaps between their outdated systems and cutting-edge technologies. As a Data Modernization consulting partner, Bitwise helps solve some of the most difficult challenges of modernizing legacy EDW in the cloud.
With Microsoft announcing general availability of Fabric in late 2023, organizations are lining up to take advantage of the latest analytical potential of the combined platform. For organizations with Teradata EDW, there can be a high degree of risk to completely modernize with Fabric. Bitwise helps organizations that want to quickly take advantage of cloud cost savings but are not ready for a complete modernization by migrating and stabilizing Teradata EDW to Teradata Vantage on Azure as a stopover solution before modernizing with a ‘better together’ Lakehouse/Fabric architecture for an advanced analytics solution in the cloud.
Organizations with legacy ETL (extract, transform, load) tools like Informatica, DataStage, SSIS (SQL Server Integration Services), and Ab Initio that want to take advantage of programmatical data processing frameworks like Azure Databricks utilizing data lakehouse architecture will find that migration can be a risky proposition due to incompatibility and high probability for human error. This is where Bitwise can overcome challenges and eliminate risk with its AI-powered automation tools backed by years of ETL migration experience to convert legacy code to PySpark for execution in Azure Databricks for improved flexibility to meet modern analytics and AI requirements.
Conclusion
In the ever-evolving landscape of data processing and analytics, Databricks and the Data Lakehouse concept stand as guiding beacons for modern organizations. As with all technologies, change is constant and implementing a data lakehouse architecture can provide the flexibility to stay on pace with future requirements. With generative AI taking the world by storm, the importance of having the optimal architecture to ensure data accessibility, accuracy and reliability is greater than ever. Working with a consulting partner that knows the ins and outs of both traditional data warehouse systems and the latest data platforms, along with automated migration tools, can help efficiently modernize your data to best meet your current and anticipated analytics needs.

You Might Also Like



Data Security

