Babatunde Ogunnaike and W. Harmon Ray , two chemical engineering professors, wrote a famous book on process dynamics in 1995.
It says some processes, given a defined set of inputs, would generate the same set of outputs every time. These are defined processes where the dynamics can be tightly controlled and its output, at various stages, can be definitively predicted.
Processes, which do not show similar predictable behavior, need to be controlled using something called empirical process control. These processes gather data through frequent inspections at regular checkpoints and adaptation to changing scenarios.
Ring a bell?
The biggest shift brought by Agile (compared to traditional Waterfall methods) is not the way software development projects are executed. It is the way the dynamics of software development are understood.
What to Explore
The Science of Iterations
Volatile business needs and a core reliance on human skills and creativity induce an inherent uncertainty in software development processes. This makes it unrealistic to define the processes and expect a uniform output every time.
Ken Schwaber, one of creators of Scrum, studied Ogunnaike’s process controls at DuPont. He found that software development, just like any other empirical process, needed a way to check process performance while it was in progress to make sure it was on the correct path. Iterations or sprints are the natural checkpoints to measure the output and adapt in the way you proceed.
The Science of Story Points
Why use story points? They are not even real, right? Let’s see about that.
The traditional approach of estimation has been to break down the work and then assign the amount of time an “ideal” developer would take to accomplish it. These ideal estimates (in days or hours) are based on some assumptions about the rate at which software can be produced by this fictitious developer. The assumed productivity rate is based on various factors such as skills, experience, coding style, etc.
The story point approach makes it simple and data driven. These are hypothetical numbers assigned to tasks based on the amount of work expected to complete the task and the complexity involved. How could an imaginary story point be translated into the real effort spent by the team? Here’s how:
To begin with, you need to have a system in place to measure the actual hours spent by developers on tasks labelled as one story point. It’s fine if it varies by person and by team.
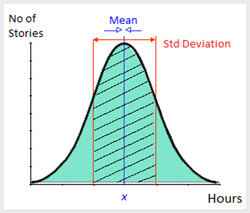
The central limit theorem The central limit theorem in probability states that the arithmetic mean of a sufficiently large number of iterates of independent random variables (hours consumed per story point in this case) will be distributed like a bell curve. This means if you plot the hours taken to build a story of size 1 story point against the number of stories on a chart, the graph will look somewhat like the diagram here. You clearly see a bell shaped pattern with a mean value “x”. Now similarly, plot the hours taken to build a story of size 2 story points, its mean will be 2x. This “x” is your conversion factor for translating story points into person hours.
What if you don’t have the historical data or a system to gather the data? Start with assigning an estimate of 1 story point to a familiar task that usually takes 8 hours.
The Science of Relative Sizing
Agile estimation techniques recommend sizing up tasks relative to each other. The estimator compares the task or story being estimated with one or more other tasks. If the task involves twice the work or is twice as complex, it is estimated twice as large.
So what are the benefits in doing that?
When you estimate tasks relative to each other, your estimation process is not only more accurate but significantly faster. There is an evidence that humans are better at estimating relative size than the absolute size (Lederer and Prasad 1998; Vicinanza et al. 1991).
Looking at a map, it’s hard to guess that the distance from New York to Chicago is 800 miles and New York to Boston is 200 miles. But it’s not so hard to tell that the distance from New York to Chicago is four times as much as the distance from New York to Boston.
The Coastline Paradox
How much effort should a project of size x take to estimate accurately? Well, the lesser the better. Estimates by definition are supposed to be just usable approximations. Estimation effort beyond a point yields very little value to the project.
The Coastline Paradox It may seem counter-intuitive but the more you break down a task to a micro level, the more are the chances that your estimate is going to be wrong.
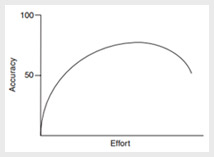
A similar challenge is experienced by surveyors trying to measure the coastline of a country. It can produce varying results depending upon the length of the scale chosen for the job.
With a smaller the scale, and you can measure every little crevice along every creek on the shore. Take a bigger scale and it smooths out all details. This paradox of a constant finite area having varying length of perimeter is called coastline paradox.
In short, whether you are estimating efforts or measuring a coastline, choose the level of detail you want to consider wisely. Living with a measure of ambiguity at times will not only save your efforts but will also increase effectiveness of your efforts. Sound counter-intuitive? That’s why it’s called a paradox.
Conclusion
During one of their discussions at DuPont, when Schwaber mentioned that the success rate of their software development projects were around 50%, Ogunnaike remarked that it was like GM throwing away every other car it made. With Waterfall, that has been the unfortunate reality.
Think it’s time to improve software delivery in your organization? We can help.
Recommended Content

You Might Also Like


Data Security
Implementing Fine-Grained Data Access Control: A Complete Guide to GCP Column-Level Policy Tags
Learn More



